中国采购招标网数据采集
URL ,通过爬虫去请求该网站会返回521状态码,需要带着特定cookie去访问,此cookie又是动态变化,如果想要持续采集就得破解此cookie生成规则。
站点反爬分析
通过Fiddler抓包分析,可以看出它的请求顺序。
- 首次发起请求,返回状态码为521,返回第一段加密cookie,携带第一段加密的cookie去请求会返回第二个521状态码,会返回第二段加密cookie,然后携带第一段和第二段cookie去请求页面,才返回正常状态码,通过观察第二段加密cookie有时效性,一会就过期,破解步骤见下面。


- 第一段加密cookie具体内容:整个script中包含两部分内容,(1):通过js生成的第一段加密cookie;(2):第二个加密cookie页面的跳转,这部分破解比较简单,借助python的execjs包去模拟执行js,然后返回加密cookie即可。
| 获取请求的set_cookie,返回内容为:__jsluid_h=7cad7d7e20bf090ce259b49c85542372(此参数在后续请求均需携带);执行js返回的document.cookie内容:__jsl_clearance=1603345157.389 | -1 | HI%2B0JxwfexVK0OVf0WEG4FxNW3A%3D,一开始以为这就是破解成功的cookie,谁知道注意观察后返回200状态码的请求cookie格式为:XXX | 0 | XXXX 而此次请求返回中间部分为-1,只有请求第二个加密js后才能获取正确cookie。 |
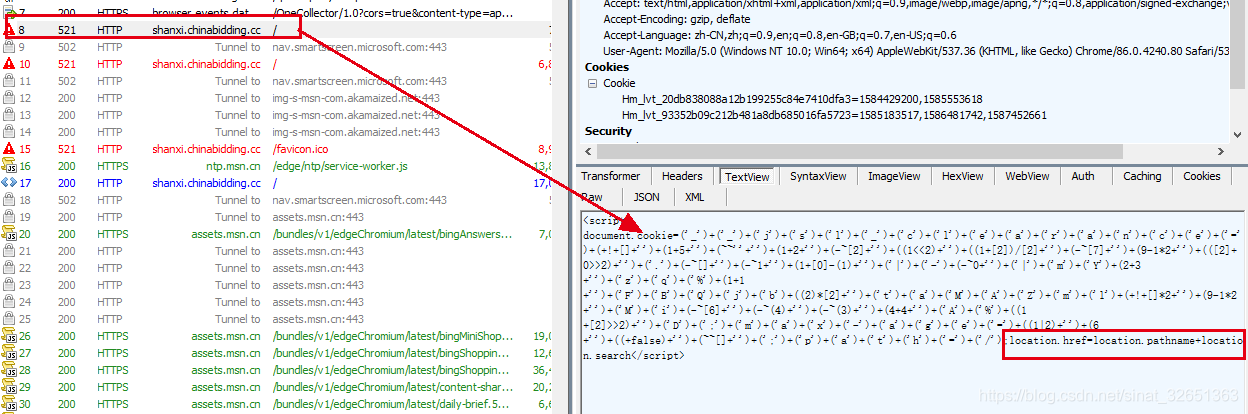 第一段加密cookie
第一段加密cookie
代码片段:
def first_cookie_decode(base_url):
"""
破解首次加密
:param base_url: 原始请求URL
:return: 浏览器请求头,首次破解加密字段一
"""
response = requests.get(base_url, headers=HEADERS, timeout=(8, 8))
if response.status_code == 521:
cookies = response.cookies
str_js_cookie = response.text.replace("<script>document.", "").replace(
";location.href=location.pathname+location.search</script>", "")
print("0. 待破解字段==>", str_js_cookie) # 替换掉页面跳转部分JS
# 获取加密字段内容
js_result = execjs.eval(str_js_cookie).split(";")[0] # 执行加密JS
print("1. 待破解加密字段一==>", js_result)
cookies_text = ';'.join(['='.join(item) for item in cookies.items()])
print("2. 加密字段一==>", cookies_text) # 此字段可连续使用
HEADERS['cookie'] = cookies_text + "; " + js_result
else:
print("状态不为521,可直接使用-first_cookie_decode")
return HEADERS, cookies_text
- 第二段加密cookie具体内容:
首先整个页面的JS是通过不同编码搞成了乱码,无法直接查看JS具体内容,但是通过第三方js执行工具执行发现执行后总是会跳转页面,因此考虑会和第一段浏览器跳转一样,最后发现了go()方法,而且看到go()方法调用的参数bts为我们需要的破解参数,破解与未破解区别如下:
未破解: 1603071828.236 0 nuN 4FZAvCZ1Ba7ZTI%2B%2FKxzFJY%3D 执行第二段JS破解后的cookie:1603071828.236 0 nuN vi 4FZAvCZ1Ba7ZTI%2B%2FKxzFJY%3D
发现原来的bts参数后面部分多了两位字母,长达300多行的js就干了一件事,通过入参与浏览器的请求头(很重要)生成了加密的两位字母并拼接到了第二段加密cookie中。第二段js本想通过本地execjs执行,但是发现js代码片段中包含对浏览器配置的获取,因此本地无法执行,则考虑selenium去尝试,结果本机的chrome86.0版本死活无法加载该js,目前有什么配置暂不清楚,一直降级发现chrome73.0版本支持该js执行并加载。关于此部分js内容破解,通过阅读该js源码发现有部分:“document[_0x197c(‘0x35’, ‘g%4U’) + ‘ie’]”和:“location[_0x197c(‘0x49’, ‘5@s1’)]”,很明显location控制跳转,我们只要对document部分内容做破解即可,document内容(这是它执行自己内部函数的关键):
_0x1d288_0x197c(‘0x61’, ‘(zd#’) + ‘J’ + ‘J’](_0x1d288_0x197c(‘0x86’, ‘&91$’) + ‘V’, _0x1c6092[0x0]) + (_0x197c(‘0x5a’, ‘kUvB’) + _0x197c(‘0x2b’, ‘T@q(‘) + ‘=’) + _0x54977a[‘vt’], _0x197c(‘0x77’, ‘3Z!!’) + _0x197c(‘0x2a’, ‘Qi@k’) + ‘\x20/’);
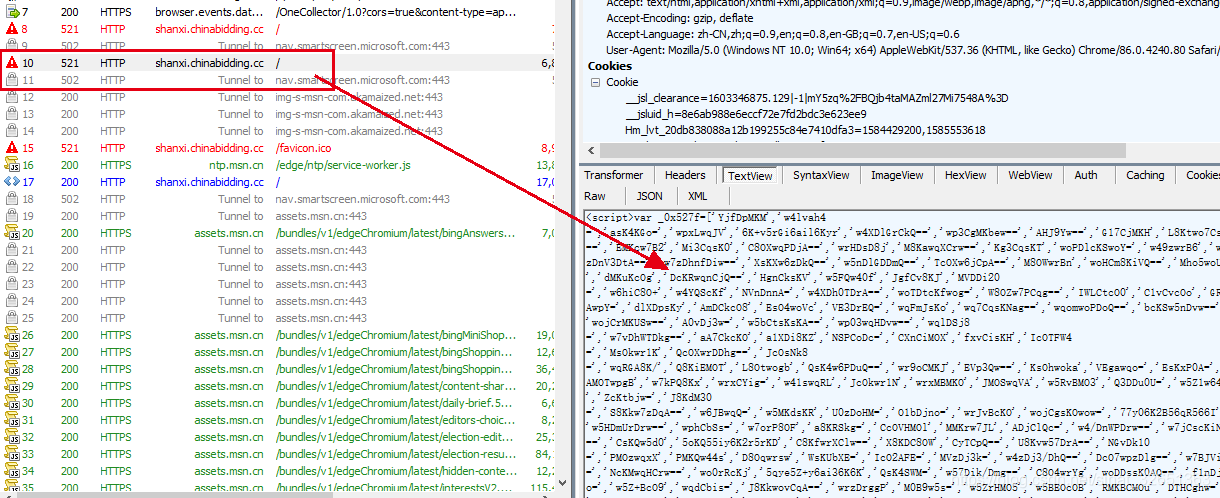 第二段加密cookie的JS内容
第二段加密cookie的JS内容
 第二段加密cookie具体细节
第二段加密cookie具体细节
- 破解流程:
- 发起首次请求返回521状态,获取本次请求的set_cookie,并获取加密js内容:__jsluid_h=7cad7d7e20bf090ce259b49c85542372;
-
携带__jsluid_h和set_cookie发起第二次请求:__jsl_clearance=1603345157.389 -1 HI%2B0JxwfexVK0OVf0WEG4FxNW3A%3D:获取正确的第二部分加密JS内容; -
通过第二部分加密js内容__jsl_clearance,使用selenium执行返回正确的__jsl_clearance=1603345157.389 0 HI%BV2B0JxwfexVK0OVf0WEG4FxNW3A%3D; - 携带__jsluid_h、__jsl_clearance去再次请求,返回正确状态码:200及真实页面内容。(整个过程必须使用同一浏览器,否则加密参数不一致)
- 详细代码
#!/usr/bin/python3
# encoding: utf-8
"""
@version: v1.0
@author: W_H_J
@license: Apache Licence
@contact: 415900617@qq.com
@software: PyCharm
@file: cookieDecodeJs.py
@time: 2020/10/19 21:32
@describe: 中国采购招标网COOKIE解密JS破解
http://shanxi.chinabidding.cc/
"""
import sys
import os
import time
from requests.adapters import HTTPAdapter
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from pyquery import PyQuery as pq
import execjs
import requests_html
sys.path.append(os.path.abspath(os.path.dirname(__file__) + '/' + '..'))
sys.path.append("..")
SESSION = requests_html.HTMLSession()
SESSION.mount('http://', HTTPAdapter(max_retries=6))
SESSION.mount('https://', HTTPAdapter(max_retries=6))
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Host': 'shanxi.chinabidding.cc'
}
def first_cookie_decode(base_url):
"""
破解首次加密
:param base_url: 原始请求URL
:return: 浏览器请求头,首次破解加密字段一
"""
response = SESSION.get(base_url, headers=HEADERS, timeout=(8, 8))
if response.status_code == 521:
cookies = response.cookies
str_js_cookie = response.text.replace("<script>document.", "").replace(
";location.href=location.pathname+location.search</script>", "")
print("0. 待破解字段==>", str_js_cookie)
# 获取加密字段内容
js_result = execjs.eval(str_js_cookie).split(";")[0]
print("1. 待破解加密字段一==>", js_result)
cookies_text = ';'.join(['='.join(item) for item in cookies.items()])
print("2. 加密字段一==>", cookies_text) # 此字段可连续使用
HEADERS['cookie'] = cookies_text + "; " + js_result
else:
print("状态不为521,可直接使用-first_cookie_decode")
return HEADERS, cookies_text
def second_cookie_decode(base_url):
"""
破解第二段加密cookie
:param base_url: 原始请求URL
:return: 破解完的加密js代码片段,通过内部api请求模拟获取最终加密结果,此结果可多次使用
"""
HEADERS_F, cookies_first_decode = first_cookie_decode(base_url) # 浏览器请求头,第一个加密字段
response = SESSION.get(base_url, headers=HEADERS_F, timeout=(8, 8))
if response.status_code == 521:
text_second_521 = response.text
js_cookie = text_second_521[text_second_521.find('go({"bts":[') + 12:text_second_521.find('"],"chars')].split(
'","')
print("3. 待破解加密字段二==>", js_cookie[0] + js_cookie[1])
# 二次破解cookie加密字段
str_base = text_second_521
print("4. 待破解字段三==>", str_base)
str_ie_cookie = str_base.replace(" ", "")[
str_base.replace(" ", "").find("'ie']=") + 6:str_base.replace(" ", "").find("location[")]
print("5. 破解的加密JS内容==>", str_ie_cookie)
str_cookie_temp = '''var cookies={}\nreturn cookies;'''.format(str_ie_cookie)
str_base_temp = str_base[str_base.rfind(")]);if(") + 4:str_base.rfind("}};go({") + 1]
str_back_fun = '''var str_back = back();console.log(str_back); setTimeout(function() {document.getElementById('cookieId').innerHTML=str_back;}, 500);'''
str_js_cookie = str_base.replace(str_base_temp, str_cookie_temp).replace("go({",
"var back_cookie = go({").replace(
"})</script>", "}); return back_cookie;}" + str_back_fun).replace("<script>", "function back(){")
with open("./statisticalDataSpider/spider/business/cookieDecode/static/cookie_js.js", 'w', encoding="utf-8") as f:
f.write(str_js_cookie) # 保存二次加密的js到本地然后通过本地起一个服务,使用selenium执行,获取正确的加密cookie
else:
print("状态不为521,可直接使用")
return cookies_first_decode, response.status_code
def third_cookie_decode(status_code):
"""
进行第二次解密参数破解
:return: __jsl_clearance=1603095437|0|IIfaCCOxqoEKlTN7dqVU%2Blb2ypw%3D
"""
# 需要chrome及chromdriver均需使用版本73.0
if status_code == 521:
options = ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
# options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
options.add_argument('user-agent="{}"'.format(HEADERS['User-Agent']))
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
chrome_path = r"./statisticalDataSpider/spider/business/cookieDecode/static/chromedriver.exe"
browser = webdriver.Chrome(executable_path=chrome_path,options=options)
browser.get('http://127.0.0.1:9093/cookie') #自己起了一个本地服务,让selenium执行js
time.sleep(5)
page = browser.page_source
doc = pq(page)
js_cookie = doc("#cookieId").text()
browser.close()
if js_cookie != "undefined" and js_cookie != "默认":
third_cookie = js_cookie.split(";")[0]
return third_cookie
else:
return None
def get_decode_cookie(base_url):
"""
最终破解成功的cookie
:param base_url: 原始URL
:return:
"""
cookie_first_decode, status_code = second_cookie_decode(base_url)
cookie_second_decode = third_cookie_decode(status_code)
if cookie_second_decode is not None:
print("6. 破解加密字段一成功==>", cookie_first_decode)
print("7. 破解加密字段二成功==>", cookie_second_decode)
HEADERS['cookie'] = cookie_first_decode + "; " + cookie_second_decode
print("8. 解密后的Headers==>", HEADERS)
return HEADERS
else:
return None
def get_html(base_url):
headers = get_decode_cookie(base_url)
html = SESSION.get(base_url, headers=headers, verify=False, timeout=(5, 5))
print("9. 最终返回状态码==>", html.status_code)
print("BODY", html.text)
return html.status_code, html.text
if __name__ == '__main__':
url = 'http://shanxi.chinabidding.cc/lists.html?page=4&zz=city_119&keyword=%E8%A5%BF%E5%AE%89%20%E8%A5%BF%E5%AE%89&pid=9&city=120&time=1'
get_html(url)